一、频数表的编制与频数分布
计量资料有离散型变量和连续型变量。对离散型变量,可列出变量值及其频数如表4.1。若变量值较多时,亦可用组段表示如表4.2。每个组段的起点称下限,终点称上限,上限与下限之差称组距。如表4.2第一组的下限是0,上限是1。第二组的下限是2上限是3,组距都是1。归组以后,该组的变量值用组段的中值代表,称组中值。如第一组的组中值为0.5。
表4.1 某市居民1095天中每天意外死亡人数(1980~82年)
| 死亡人数 | 天数 |
| 0 | 807 |
| 1 | 250 |
| 2 | 31 |
| 3 | 5 |
| 4 | 0 |
| 5 | 0 |
| 6 | 0 |
| 7 | 1 |
| 8 | 0 |
| ┆ | ┆ |
| 15 | 1 |
| 合 计 | 1095 |
表4.2 204名轧钢工人白细胞中大单核所占百分比
| 大单核数(个/每百白细胞) | 人数 |
| 0-1 | 24 |
| 2-3 | 40 |
| 4-5 | 55 |
| 6-7 | 37 |
| 8-9 | 27 |
| 10-11 | 18 |
| 12-13 | 1 |
| 14-15 | 0 |
| 16-17 | 1 |
| 18-19 | 0 |
| 20-21 | 1 |
| 合计 | 204 |
若是连续型变量,组段的写法与离散型变量的略有不同。如表4.3坐高第一组段下限为61,上限为62;第二组段的下限为62,上限为63。因此,上一组段的上限和下一组段的下限值相同。为便于归组,上限一般不写出来。如第一组写成“61-”,意思是凡坐高在61至未离散型变最的数值较大时,亦可按连续型变量写组段,如红细胞数(万/mm3)的组段应写成400-419,420-439,…,亦可简化写成400-,420-,…。这样由组段和频数两部分组成的表称为频数表。下面用表4.4资料说明频数表编制步骤。??
表4.3 某市7岁男童坐高频数表

表 4.4 西安市7岁男童102人的坐高,cm
| 64.4 | 63.8 | 64.5 | 66.8 | 66.5 | 66.3 | 68.3 | 67.2 | 68.0 | 67.9 |
| 63.2 | 64.6 | 64.8 | 66.2 | 68.0 | 66.7 | 67.4 | 68.6 | 66.8 | 66.9 |
| 63.2 | 61.1 | 65.0 | 65.0 | 66.4 | 69.1 | 66.8 | 66.4 | 67.5 | 68.1 |
| 69.7 | 62.5 | 64.3 | 66.3 | 66.6 | 67.8 | 65.9 | 67.9 | 65.9 | 69.8 |
| 71.1 | 70.1 | 64.9 | 66.1 | 67.3 | 66.8 | 65.0 | 65.7 | 68.4 | 67.6 |
| 69.5 | 67.5 | 62.4 | 62.6 | 66.5 | 67.2 | 64.5 | 65.7 | 67.0 | 65.1 |
| 70.0 | 69.6 | 64.7 | 65.8 | 64.2 | 67.3 | 65.0 | 65.0 | 67.2 | 70.2 |
| 68.0 | 68.2 | 63.2 | 64.6 | 64.2 | 64.5 | 65.9 | 66.6 | 69.2 | 71.2 |
| 68.3 | 70.8 | 65.3 | 64.2 | 68.0 | 66.7 | 65.6 | 66.8 | 67.9 | 67.6 |
| 70.4 | 68.4 | 64.3 | 66.0 | 67.3 | 65.6 | 66.0 | 66.9 | 67.4 | 68.5 |
| 68.3 | 69.7 |
(一)找出原始资料中的最小、最大值 表4.4坐高的最大值为71.2cm,最小值为61.1cm,最大值与最小值之差称极差为10.1cm。
(二)定组距 先考虑组数。资料在100例以上的一般分10-15组。若例数较少,组数可相应少些;例数很多,组数可酌情多些,以能显示分布的规律为宜。此例拟分10组。将拟分的组数除极差(10.1/10≈1)得组距的约数。再调整到较方便的数如0.1、0.2、0.5,1、2、5、10、20、50……等。此例取组距为1。
(三)写组段 取等于或略小于最小值的整数为第一组的下限。按组距依次写出各组段的下限及短横,见表4.3组段行,注意短横“-”不能略去。
(四) 划线记数 像选举开票那样,将变量值逐个归入相应的组段,如将64.4归入“64-”组,63.8归入“63-”组。每归入一个变量值,在相应的组段内划一竖线,每逢第五线则作一横线跨在已划出的四条竖线上,这样五线连在一起最后计数时就很方便了。划完后将每个组段内的线条数写出,再将各组频数合计,频数表就编好了。
若事先不能确定合适的组数,可先分细些,需要时再将相邻两组合并。而分粗了,再要分细,则只得重划。
表4.4的资料编成频数表(见表4.3)后,可看出变量值的分布情况,若绘成直方图就更直观。从图4.1可看到横坐标约为66.5cm处直方最高,表示变量值围绕在66.5左右的最多;两侧对称下降,大于66.5和小于66.5的变量值个数基本相等。这种类型的分布为对称分布。第五章介绍的正态分布是其中最常见的一种。
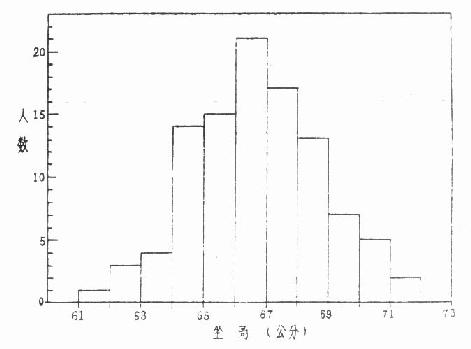
图4.1 西安市7岁男童坐高分布
此外,如图4.2,变量值愈小频数愈多图形呈“L”形,图4.3的频数集中在变量值较小的一边,右侧尾部拖得很长。后两种属偏态分布。这三种频数分布都只有一个高峰称单峰分布。为更准确地说明分布的特征,对形状相同的分布作出集中位置和离散程度的比较,就需计算频数分布的一些特别值。如平均数、百分位数、极差、标准差、变异系数等。
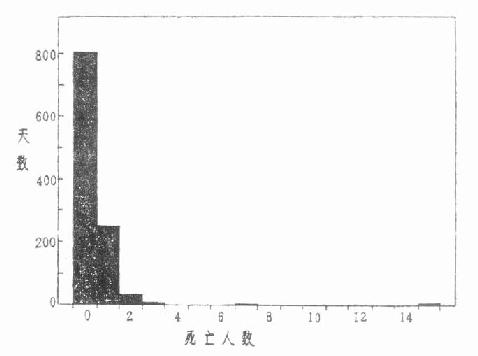
图4.2 某市1095天中居民意外死亡人数(1980-1982)
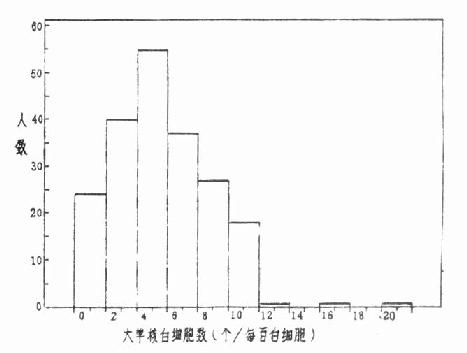
图 4.3 204名轧钢工人白细胞中大单核所占百分比
二、众数、中位数、百分位数的意义及计算法
(一)众数 出现次数最多的变量值,或频数表上频数最多组的组中值即为众数。如表4.3中坐高的众数是66.5cm。这样仅由观察所得的众数称为观察众数。同一资料常因所用组距不同和下限取值不同,观察众数稍有出入,故又称概约众数,与观察众数相对应的尚有理论众数。理论众数的算法根据频数曲线类型的不同而异,数学上为与极大值相应的横坐标。
(二)中位数及百分位数
1.中位数 将n个变量值从小到大排列后,居中的一数就是中位数,符号为M,有的书上用Md。它将变量值分为两半,一半比它小,一半比它大。
X1<X2<…<M<…Xn-1<Xa
当n为奇数时
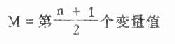
(4.1)
当n为偶数时

(4.2)
当资料呈明显偏态,或有个别的特小、特大值存在时,中位数的代表性往往比均数好。例如有5个变量值8、9、9、10、19。其中4个在9左右,但由于受数值19的影响,均数为11,不能很好代表中等水平。求中位数

比较符合实际。
根据频数表计算连续型变量的中位数可用式(4.3)或式(4.4)
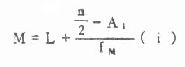
(4.3)
或
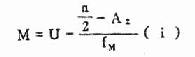
(4.4)
式中L、U分别为中位数所在组的下限及上限,A1为小于L的各组的累计频数,A2为大于U的各组的累计频数,fM、i分别为中位数所在组的频数和组距。现用表4.5说明计算步骤如下:
(1)求出中位数的位置。在频数表上,数据已由小到大排好了。中位数将频数等分为2,因此先计算n/2,得中位数的位置。
n/2=157/2=78.5
(2)列出频数表、计算累计频数。列频数表时,组段的短横“-”写在两个组段下限之间,其意义仍与写在右边的相同,见表4.5第(1)栏。
第(3)栏为累计频数。此例自上而下累计到略小于n/2为止得A1=41,表示住院天数为10天及以下的有41个人。若要知道第78.5人的变量值,就需要从10-15组内再累计(78.5-41=)37.5人。假定该组的49人在10-15天内均匀分布着(见图4.4),那么只要在10天上再加(78.5-41)/49个组距便是中位数了。所以
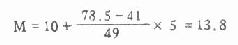
用符号表示见式(4.3)。
若将频数自下而上累计到略小于n/2为止,则得A2=67。也得出中位数在10-15组段内。
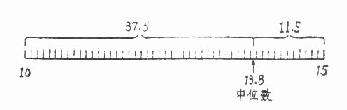
图4.4 中位数计算示意图
(3)写出L或U、fM及i。
(4)代入公式得M。
例4.1 求杆菌痢疾治愈者157名住院天数的中位数。
n/2=157/2=78.5
表4.5 杆菌痢疾治愈者的住院天数

L=10或U=15,fM=49,i=5。
代入公式
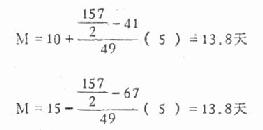
杆菌痢疾治愈者住院天数的中位数为13.8天。
中位数既然把频数等分为二,所以从另一端算起,用式(4.4)可得到同样的结果。
此例若计算治愈者平均住院天数得17.9天。从频数表上可看到157名患者中住院天数少于15天的就有90名,占57.3%,因此中位数13.8天的代表性优于均数17.9天。
2.百分位数 中位数将频数等分为二,亦称二分位数。若将频数等分为四,则称四分位数,共有三个四分位数,即第一、第二、第三四分位数。第二四分位数即中位数。同理,将频数等分为十或一百的分位数称十分位数或百分位数。其实上述各种分位数都可用百分位数表示。百分位数的符号为Px,X代表第X百分位。例如第一四分位数、中位数可分别以P25、P50表示。计算百分位数的方法与中位数相似,只是式(4.3)中的n/2以nx/100代替,M以X代替。
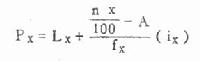
(4.5)
式中LX、fx、ix分别为Px所在组的下限、频数及组距。A为小于Lx各组的累计频数。
例4.2,求例4.1中住院天数的P90。
(1)计算
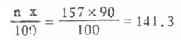
(2)累计频数自上而下至略小于141.3,见表4.5第(4)栏,得A=135。知P90在30-35组内,因此Lx=30,i=5,fx=7
(3)代入公式
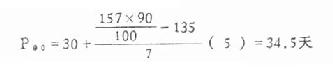
第90百分位数为34.5天,说明有90%的患者住院天数在34.5天以下。
三、算术均数与几何均数的意义及计算方法
(一)算术均数 简称均数。设观察了n个变量值X1,X2,……Xa,一般可直接用式(4.6)求样本均数X。
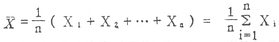
式中∑是总和的符号,n是样本含量即例数。本书在不会引起误解的情况下简写成
X=1/n∑X (4.6)
例4.318-24岁非心脏疾患死亡的男子心脏重量(g)如下,求心重的均数。
| 350 | 320 | 260 | 380 | 270 | 235 | 285 | 300 | 300 | 200 |
| 275 | 280 | 290 | 310 | 300 | 280 | 300 | 310 | 310 | 320 |
X=1/20(350+320+…+320)=5875/20=293.75g
样本均数是总体均数的估计值,它有两个特性。(1)∑(X-X)=0,(2)∑(X-X)2为最小,前者读者
可自证,后者证明如下:
设:a≠X,则a=X±d d>0
∑(X-a)2=∑(X-X±d)2
=∑[(X-X)±d]2
=∑(X-X)2±2d∑(X-X)+Nd2
从第一个特性知∑(X-X)=0,因此2d∑(X-X)=0,
得
∑(X-a)2=∑(X-X)2+Nd2
N是例数,不可能为负,所以Nd2也不会是负数。
∑(X-a)2>∑(X-X)2,∑(X-X)2为最小。
当用电子计算机处理大量实验数据,考虑到有较大舍入误差时,则先取一较近均数的常数c ,然后用式(4.7)计算,可提高均数的精度。
X=C+1/n×(Xi-C) (4.7)
若每输入一个变量值后都希望得到均数,那么可用式(4.8)
X=X n-1+1/n×(Xn-Xn-1 (4.8)
例4.4 仍用例4.3资料,已算得前19例心重的X10=292.37,又测得X20=320,求X20。
X20=292.37+1/20×(320-292.37)=293.75g
若相同的变量值个数较多,或对频数表资料求均数时,可用式(4.9)计算X。
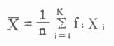
或简写为X=1/n∑fX (4.9)
式中K为不同变量值个数,或频数表中的组段数。Xi为第i个不同的变量值或频数表上的组中值,fi为第i个变量值的频数。
例4.5 计算表4.5菌痢治愈者的平均住院天数。
X=1/157(3×2.5+38×7.5……+1×77.5)=17.9天
式(4.9)中某变量值的频数愈大,则该变量值对X的影响亦愈大。因此,频数又称权数,这样
计算出来的均数又叫加权均数。亦有根据变量值的重要性进行加权,计算加权均数的。
(二)几何均数 设n个变量值X1,X2,……,Xa呈对数正态分布,其几何均数G为

式中∏为连乘的符号。当变量值较多时,乘积很大,计算不便,常改用下式计算
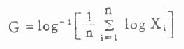
(4.10)
或
(4.11)
式中符号含义同式(4.6)与式(4.9)。
例4.6 求下表中麻疹病毒特异性IgG荧光抗体的平均滴度。
表4.6 52例麻疹患者恢复期血清麻疹病毒
特异性IgG荧光抗体滴度
| IgG滴度倒数 | 例数 |
| 40 | 3 |
| 80 | 22 |
| 160 | 17 |
| 320 | 9 |
| 640 | 0 |
| 1280 | 1 |
G=log-1[1/52×(3log40+22log80+…+log1280)]=129.3
麻疹患者恢复期血清麻疹病毒特异性IgG荧光抗体的平均滴度为1:129。
式(4.10)包含三个步骤,(1)令Xi=logXi,则式(4.10)可写成
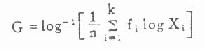
;(2)1/n∑Xi
即对数数值的均数X;(3)将X取反对数即得几何均数1og-1X=G。这里不难理解,若将这种资料作对数变换后,即可用式(4.6)至式(4.9)的各式计算均数,得到结果后再取反对数即得几何均数。读者可自已验证。
四、运用平均数的注意事项
平均数是描述一群同质变量值集中位置的特征值,用来说明某现象或事物数量的中等水平。通常用平均数作为算术均数、几何均数、众数、中位数等的统称,而以均数作为算术均数的简称。
1.同质的事物或现象才能求平均数 我们检查200名正常人的红细胞数(万/mm3)计算平均数,定出正常值范围,作为诊断贫血的依据之一。如果正常人中混有贫血患者,那么求出的平均数既不能说明正常人也不能说明贫血患者,有人把它称为虚构的平均数,因为它模糊了数量特征,不能提供分析的依据了。因此计算平均数以前必须考虑资料的同质性。有人研究某药物的利尿作用,观察了二条狗、三头兔子用药前后的排尿滴数,曾将狗与兔子的排尿滴数加在一起求平均数。由于狗体大,排尿滴数较兔子的多,得到的平均数对狗来说似嫌少,而对兔子来说又显得太多,这是虚构平均数的又一例。
像狗与兔子,贫血患者与正常人的不同质是显而易见的。但即使是正常人,性别、年龄、地区不同,红细胞数的均数也有差异。那么怎样才算是同质呢?是否同质,要根据研究目的而定。例如研究痢疾患者的平均治愈日数时,要考虑不同病原菌、不同型别(急性、慢性等)的患者是不同质的。但当研究传染病的住院日数时,则不同疾病(痢疾、伤寒、……)是不同质的,而所有痢疾病人,不论由何种病原菌引起,或是何种型别都认为是同质的了。若研究各医院的平均住院天数时,医院类型(传染病院、儿童医院、综合医院、……)以及同类医院中,科室(内、外、传染……)设置及床位分配不同等就是不同质的了。不同质的事物就要分组求平均数,以便分析比较。因此科学的平均数是建立在分组的基础上的。
2.用组平均数补充总平均数 表4.7是某院1983年的治愈者平均住院天数。总均数为18天。但从表中可见,它所包含的20类(其他类除外)的疾病中,变态反应及中毒、小儿科疾病住院天数最短为9天,而结核病的却长达60天。住院天数高于总均数的有10类,治愈人数共1358人,占治愈总人数(其他类除外)的35%。若医疗质量基本不变,多收结核病人,住院天数的总均数无疑会延长;而多收小儿患者,总均数就会缩短。因此如没有收容病种的分析,仅从总均数的延长或缩短来看医疗质量是不科学的。而对各时期同种疾病的住院天数进行分析,比较适宜。
表4.7某医院1983年各类疾病治愈者的平均住院天数
| 病类 | 治愈人数 | 平均住院天数 | 病类 | 治愈人数 | 平均住院天数 |
| 传染病寄生虫病 | 437 | 13 | 外科疾病 | 549 | 18 |
| 结核病 | 109 | 60 | 外伤 | 383 | 28 |
| 呼吸系疾病 | 246 | 14 | 肿瘤 | 65 | 34 |
| 消化系疾病 | 255 | 24 | 眼科疾病 | 112 | 14 |
| 内分泌疾病 | 41 | 35 | 耳鼻喉科疾病 | 417 | 10 |
| 循环系疾病 | 34 | 37 | 口腔科疾病 | 30 | 12 |
| 血液及造血系统疾病 | 7 | 33 | 皮肤科疾病 | 224 | 22 |
| 神经系疾病 | 111 | 25 | 妇产科疾病 | 78 | 12 |
| 变态反应及中毒 | 43 | 9 | 小儿疾病 | 601 | 9 |
| 风湿病 | 21 | 10 | 其他 | 35 | 19 |
| 泌尿系疾病 | 129 | 21 | 合计 | 3927 | 18 |
3.根据资料的分布选用适当的平均数 计量资料如是单峰对称分布,宜用均数,亦可用中位数。若是偏态分布则中位数的代表性常较均数为好。某些传染病的潜伏期、抗体滴度、细菌计数、率或比的变化速度及某些物质浓度等,其频数分布明显偏态,但经对数代换后近于正态分布的,如图4.3资料,应计算几何均数以描述其中等水平。