一、暴露组选择
暴露组应已处在某种暴露因素中或已有某种特殊暴露史,并能提供可靠的暴露因素的历史,且便于追踪与观察。
(一)特殊暴露的人群
选择由于职业关系或其他原因暴露于某危险因素特别严重的人作为定群研究对象,不但所需要的人数较少,而且较易发现暴露与患病之间是否存在联系。如研究放射线与白血病的关系时,选用接受放射线治疗的患者;研究联苯胺与膀胱癌的关系时,选用染料工人;研究肺癌的危险因素时,选用石棉工人。
(二)一个地区的全部人口或其样本
有时可在一地区人群中进行定群研究。选择条件首先是便于研究。例如,在美国马萨诸塞州的Framingham镇已进行多年的心脏病定群研究,在1948年开始时以当时30~59岁人口的2/3的一个随机样本作为研究对象。因为当地人口流动性小,居民配合,有一所高水平的医院等,便于随访,能得到完整的资料。
一个可疑病历必须有较高的人群暴露率,并且所研究的病又有较高的发病率或死亡率才适合于用全人群作定群研究。
(三)便于随访的人群
为了便于随访,往往选择一个团体,或以医疗就诊和随访观察结果方面特别方便的人群作为研究对象,可以节省人力、物力,并可提高随访质量和结果判断的可靠程度。例如Doll和Hill选择了所有登记注册的开业医生。选择属于团体的人群,样本代表全人群的可能性稍差,但是能降低失访率,同时提高调查结果的可靠性。
二、对照组的选择
对照组的设立是为了与暴露组比较。对照组与暴露组应具有可比性,即对照组人群除暴露因素的影响外,其他各种因素的影响或人群的特征,如年龄、性别、职业、民族等,都应尽可能与暴露组相似。同时在资料收集完毕,进行分析时,还应作一次均衡检验,以考核两组资料的可比性。
对照组常用以下几种形式:
(一)内对照
若调查对象是一个整体人群,人群内部暴露于某因素的便为暴露组,而非暴露或以暴露级别最低的一组便为对照组;不需另外设对照组或非暴露组。例如,调查人群中血脂水平,可以水平最低的组列为对照。
(二)人群对照
不另设对照,而是以人群为对照。在职业流行病学研究中,常以某职业人群为暴露组,与该地区整个人群的发病(或死亡)率进行比较分析。以人群为对照,应注意对照组与暴露组人群在地理与时间的一致性。
特殊暴露人群人数一般不多,不能得到可靠的分年龄、性别和原因的专率供直接比较,一般须采用标化死亡比或标化发病比作间接比较,两者均须计算标准误并作显著性检验。
(三)另设对照组
选择一个与暴露组在年龄、性别、民族、居住地区等方面相似的非暴露组作为对照组进行随访,作为与暴露组比较的基准。例如研究放射线对放射科医师死亡率的影响时,可以在同地区医院内眼科医师作对照组。
(四)多种对照
为了增强判断依据,可将上述方法综合起来,设立多种对照,进行多重比较。如内对照、人群对照、非暴露组对照等。这样可以增加判断的依据。
三、样本大小的估计
定群研究样本大小的估计应根据:
1.暴露组的事件发生率(P1)的估计值;
2.非暴露组的事件发生率(P0)的估计值;
3.第一类错误概率α;
4.第二类错误概率β。
在该4个数值确定后,可用下式估计暴露组与非暴露组需观察的人数。
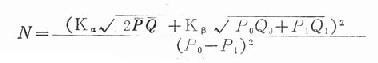
公式中N为每一组所需调查人数。
Q1=1-P1,Q0=1-P0
P=(P0+P1)/2,Q=1-P
Kα与Kβ分别为α及β值的正态分布分位数,该数可从正态分布的分位数表中查出。
非暴露组的发病率P0可以根据人群一般发病水平来代替。而暴露组的发病率P1难以估计,若能够估计相对危险度(RR),则P1=RR×P0,RR可从预调查或文献资料中估计,也可用OR来代替,P1=OR×P0,OR可从病例对照研究中得来。
例 拟用定群研究方法研究孕妇暴露于某种药物与婴儿先天性心脏病之间的联系。假定已知非暴露组的发病概率P0=0.08,估计RR=2,当α=0.05,β=0.10时,估计需要的样本含量。
Kα=1.960,Kβ=1.282
P0=0.008,RR=2,P1=2×0.008=0.016
P=(0.008+0.016) /2=0.012
Q=0.988,Q1=0.984,Q2=0.992
代入公式:
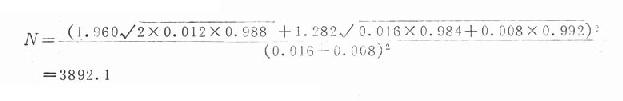
即每组需要样本含量为3892人。
四、资料的来源与收集
确定暴露组与非暴露组后,需收集对疾病的发生或死亡频率可能有影响的一般资料,如年龄、性别、婚姻、文化程度、经济收入、家庭人口、人口迁移等。
(一)从查阅现有的记录收集
特殊暴露人群的职业史或医疗记录常有暴露水平或个体暴露剂量的的资料,这是暴露史的唯一可靠来源。查阅现有记录不仅可了解研究对象本人暴露的性质和剂量,同时其主要优点是具有较高的客观性。
(二)调查询问收集
有时被研究对象的有些研究因素无现成记录,例如烟、酒、饮食等生活习惯、体力活动等,必须向被研究对象本人了解。通常采用调查表方式由调查员询问时填写或通信调查。
(三)通过医学检查或检验收集
有些研究因素属于被研究对象对生理特征或生化指标,必须通过检查或检验才能获得数据,例如血压、身高、体重、血脂、血糖等。
(四)从环境资料收集
环境资料包括家庭环境、居住环境、工作环境、区域环境等。根据不同的研究假设,可作不同暴露的测定。
(五)追踪结局收集
追踪确定各成员的结局,采用随访的方法进行。随访的方法有直接方法,即通过函件调查、访问调查、定期调查等。间接方法就是利用医院病历、死亡登记、疾病报告、劳保资料等,根据结局的性质选用。判断结局的标准必须在随访开始时规定,应保持稳定,以便前后比较。随访时间的长短,根据不同疾病的潜隐期、疾病的自然史及已暴露时间来确定。
五、定群研究资料分析
定群研究资料分析主要是计算各组发病率、发病密度或死亡率,其次对组间率的差异进行统计学检查,差异有统计学意义则进一步确定因素与疾病联系的强度。定群研究资料归纳见表30-2。
表30-2 定群研究资料归纳表
| 组别 | 病例 | 非病例 | 合计 | 发病率 |
| 暴露组 | a | b | a+b=N1 | a/N1 |
| 非暴露组 | c | d | c+d=N0 | c/N0 |
| a+c=m1 | b+d=m0 |
定群研究所比较的是发病率或死亡率即a/N1,与c/N0,如a/N1>c/N0,则某因素与发病有联系,甚至是因果联系。
(一)率的计算
1.累积发病率(cumulative incidence)观察期间人群比较固定,且能稳定地维持在一个较长的观察期,可用累积发病率(或死亡率)。计算公式为:

2.发病密度(ivcidence density)若暴露人口不固定,人群产生了较大的变动,例如由于工作调动、死于其他疾病、中途加入等,应将变动着的人群转变为人时数代替人数业计算,此种发病率称发病密度。人时就是将人与时间因素结合起来作为率分母的单位,常用的单位是人年,是一个观察对象被观察满一年计为一人年。分子为观察期间发病或死亡人数。
(二)暴露人年计算
定群研究观察时间较长,其间人口有动态变化,应采取一定方法计算“暴露人年数”,才能计算发病率;否则,两组成员由于进入开始观察的时间不同,或因死亡、迁出及其他原因或早或晚地退出该组,而造成观察时间的不同,即各组成员的暴露时间不同,可使发病率出现误差。
1.大样本中暴露人年的计算计算原则为:从观察对象中剔除死亡、迁移及失去联系的人数,补充新加入的人数来折算人年。
可以年末12月31日的人数为终点及起点计算。上年12月31日观察人数减去次年内所有死亡、迁移、失去联系及新加入人数的总和,得到次年末12月31日的观察人数。两个人数之和除以2,即得到该年内暴露人年数。表30-3为例说明不同年龄9年的合计暴露人年数。
表30-3 男性各年龄各年末存活人数
| 年龄组 | 1972.
12.31 | 1973.
12.31 | 1974.
12.31 | 1975
12.31 | 1976.
12.31 | 1977.
12.31 | 1978.
12.31 | 1979.
12.31 | 1980.
12.31 | 1981.
12.31 | 合计暴露
人年数 |
| <45 | 607 | 547 | 471 | 392 | 324 | 246 | 210 | 179 | 148 | 110 | 2875.5 |
| 45~54 | 598 | 596 | 604 | 599 | 603 | 625 | 598 | 562 | 538 | 510 | 5279 |
| 55~64 | 369 | 406 | 433 | 472 | 493 | 496 | 519 | 524 | 513 | 526 | 4303.5 |
| 65及以上 | 62 | 75 | 95 | 111 | 132 | 158 | 180 | 210 | 251 | 286 | 1386 |
| 合计 | 1636 | 1624 | 1603 | 1574 | 1552 | 1525 | 1507 | 475 | 1450 | 1432 | 13844 |
(李婉先等,1984)
以小于45岁组为例计算合计暴露人年数:
(607+547)÷2+(547+471)÷2+(471+392)÷2(392+324)÷2+(324+246)÷2+(246+210)÷2+(210+179)÷2+(179+148)÷2+(148+110)÷2= 2875.5
如此9年内共有3名45岁以下男性死亡,男性45岁以下组的死亡率为:3÷2875.5×10万=104.3/10万人年。
2.小样本可以直接计算若样本不大,且各人随访年数不同,可先算出各人随访人年数,再计算总人年数;而且因为随访期内各人的年龄在增长,到一定的日期年龄超过原属年龄组上限时,会进入下一年龄组。所以还可以算出各年龄组的总人年数以及不同的年份的总人年数,结合同年龄或同年份发生的病例数,则可算出各年龄组或年份的发病率。
例有3人从开始观察日起至1981年1月1日止,逐个计算人年的方法。上例并得出不同年龄组的暴露人年,见表30-4、表30-5。
表30-4 3例出生日期与进出研究时间
| 对象编号 | 出生日期 | 进入研究时间 | 退出研究时间 |
| 1 | 1927.03.21 | 1966.07.19 | 1977.09.14(迁居外地) |
| 2 | 1935.04.09 | 1961.11.11 | 1973.12.01(死亡) |
| 3 | 1942.11.12 | 1970.02.01 | 1981.01.01(观察结束时健在) |
资料来源:钱宇平;流行病学第二版1986
表30-5 3例人年的计算
| 对象1
1927年3月21日出生 | 对象2
1935年4月9日出生 | 对象3
1942年11月12日出生 | 暴露
人年 | |
| 25~ | 61.11.11~65.04.08
共3年4个月27天即3.41人年 | 70.02.01~72.11.11
共2年9个月10天即2.78人年 | 6.19 | |
| 30~ | 65.04.09~70.04.08
共5.00人年 | 72.11.12~77.11.11
共5.00人年 | 10.00 | |
| 35~ | 66.07.19~67.03.20
共8个月即0.67人年 | 70.04.09~73.12.01
共3年7个月22天即3.65人年 | 77.11.12~81.01.01
共3年1个月20天即3.14人年 | 7.46 |
| 40~ | 67.03.21~72.03.20
共5.00人年 | 5.00 | ||
| 45~ | 72.03.21~77.03.20
共5.00人年 | 5.00 | ||
| 50~54 | 77.03.21~77.09.14
共5个月24天即0.48人年 | 0.48 | ||
| 累计 | 66.07.19~77.09.14
共11.15人年 | 61.11.11~73.12.1
共12.06人年 | 70.0201~81.01.01
共10.92人年 | 34.13
人年 |
资料来源:钱宇平:流行病学第二版1986
(三)统计学检验
暴露组与非暴露组间率的差异要进行统计学检验。当发病率高时,可用u检验。如果发病率比较低,则改用二项分布或泊松分布检验。检验方法查阅有关统计学书籍。
(四)联系强度的测量
为了估计疾病死亡与暴露的联系强度,常用的测量指标有相对危险度、特异危险度、人群特异危险度。
1.相对危险度(relative risk)又称“危险比”(risk ratio)或“率比”(rate ratio)。是暴露组发病率(或死亡率)与非暴露组发病率(或死亡率)的比值,简称RR。
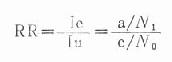
式中Ie=暴露组发病率,Iu=非暴露组发病率。
它说明暴露组发病或死亡为非暴露组的倍数。
RR>1,说明暴露因素与疾病有“正”的联系。暴露越多,发病越多,可能是致病因素。
RR=1,说明暴露因素与疾病无联系。
RR<1,说明暴露因素与疾病有“负”的联系。暴露越多,疾病越少,具有保护意义。
表30-6中提供的判断数据可供参考。
表30-6 相对危险度与联系强度
| 相对危险度 | 联系的强度 | |
| 0.9~1.0 | 1.0~1.1 | 无 |
| 0.7~0.8 | 1.2~1.4 | 弱 |
| 0.4~0.6 | 1.5~2.9 | 中等 |
| 0.1~0.3 | 3.0~9.0 | 强 |
| <0.1 | 10~ | 很强 |
2.特异危险度(attributable risk)又称归因危险度或率差(rate difference),简称AR。特异危险度为暴露组发病(或死亡)率与非暴露组发病(或死亡)率之差。
AR=Ie-Iu=a/N1-c/N0
特异危险度表示完全由暴露因素所致之危险度。
3.人群特异危险度(population attributable risk)简称PAR。
PAR=It-Iu
It=全人群某病发病率或死亡率
Iu=非暴露者某病发病率或死亡率
人群特异危险度是测量在人群中因暴露于某因素所致的发病率或死亡率。